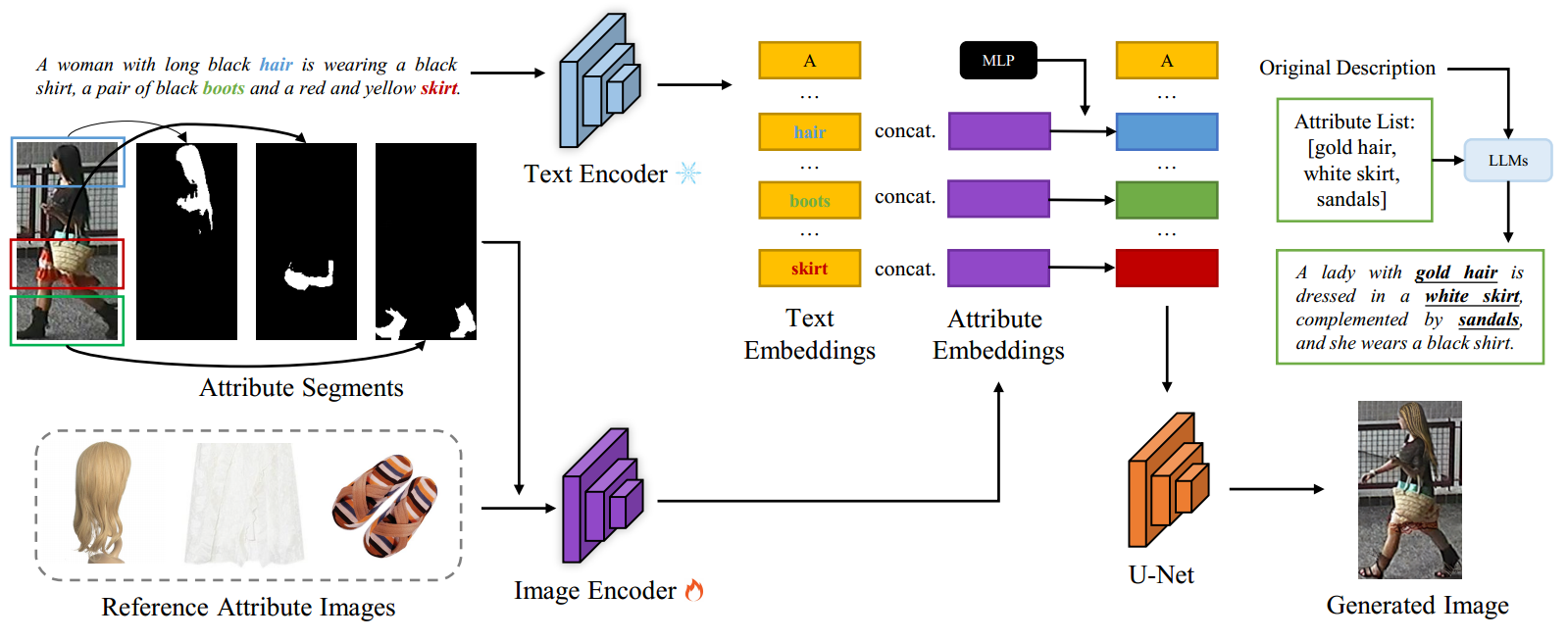
祝贺实验室团队博士生宋子帆一篇论文“Diverse Person: Customize Your Own Dataset for Text-based Person Search”被The 38th Annual AAAI Conference on Artificial Intelligence录用。针对基于文本的行人搜索数据集仍然缺乏、并且收集新的现实世界数据集存在行人隐私泄露和高标注成本等问题,本文提出了一个全新的框架,多样化行人(Diverse Person,DP),以实现高效和高质量的基于文本的行人搜索数据集生成,而不涉及隐私泄露问题。具体而言,我们提出利用互联网上的服装和配饰图像作为参考属性图像,通过扩散模型对原始数据集图像进行编辑,为了实现纯推理属性驱动的图像生成,我们将常见图片文本描述中的名词短语与目标图像中的行人属性进行匹配,然后利用大型语言模型(LLM)生成与现有现实世界数据集中的语言风格一致的高质量注释。作为一种通用方法,DP的使用方式类似于数据增强Mixaye-up(和参考属性图像的混合),本文在三个主流的文本行人搜索数据集CUHK-PEDES, RSTPReid和ICFGPEDES上验证了所提出方法对进一步提高现有SOTA方法的有效性和普适性。