祝贺实验室团队博士生赵青松一篇论文 “Adaptive Discriminative Regularization for Visual Classification” 被International Journal of Computer Vision录用。
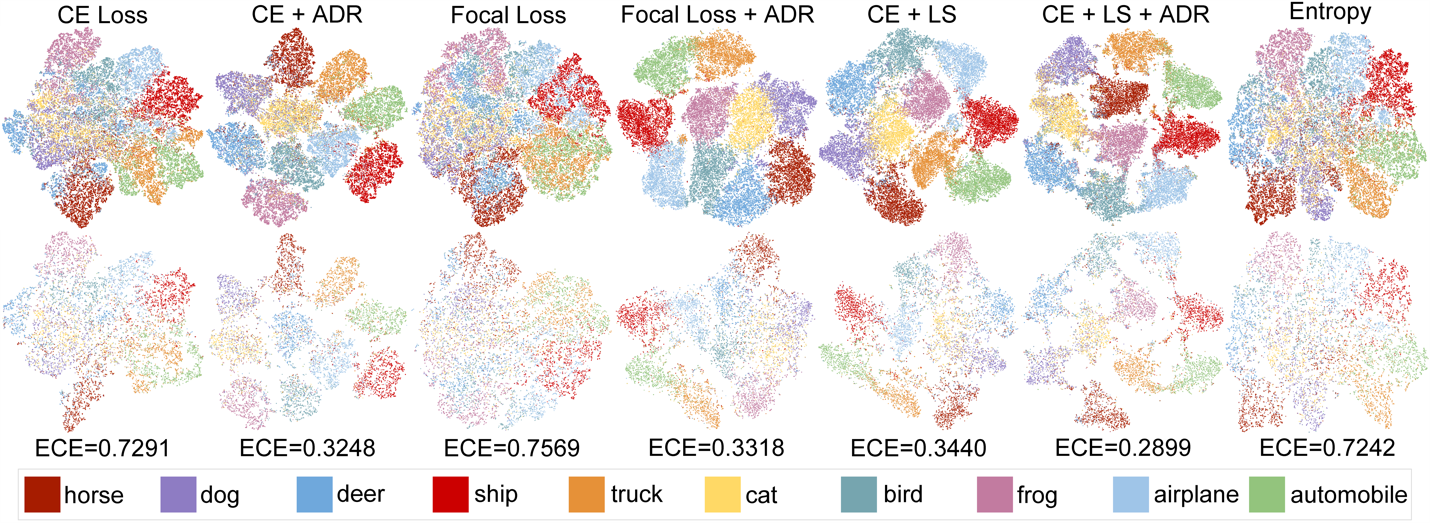
标签数据的收集很容易隐式的地包含一些人为偏置,这使得分类模型在训练的过程中很难拟合真实的类别分布(如下图b和c所示)。我们认为如何改进辨别特征学习是分类中的核心问题,现有的研究通过构建对比学习的正负样本或提出更严格的类别分隔边界,明确增加类间可分性和类内紧凑性来解决这个问题。

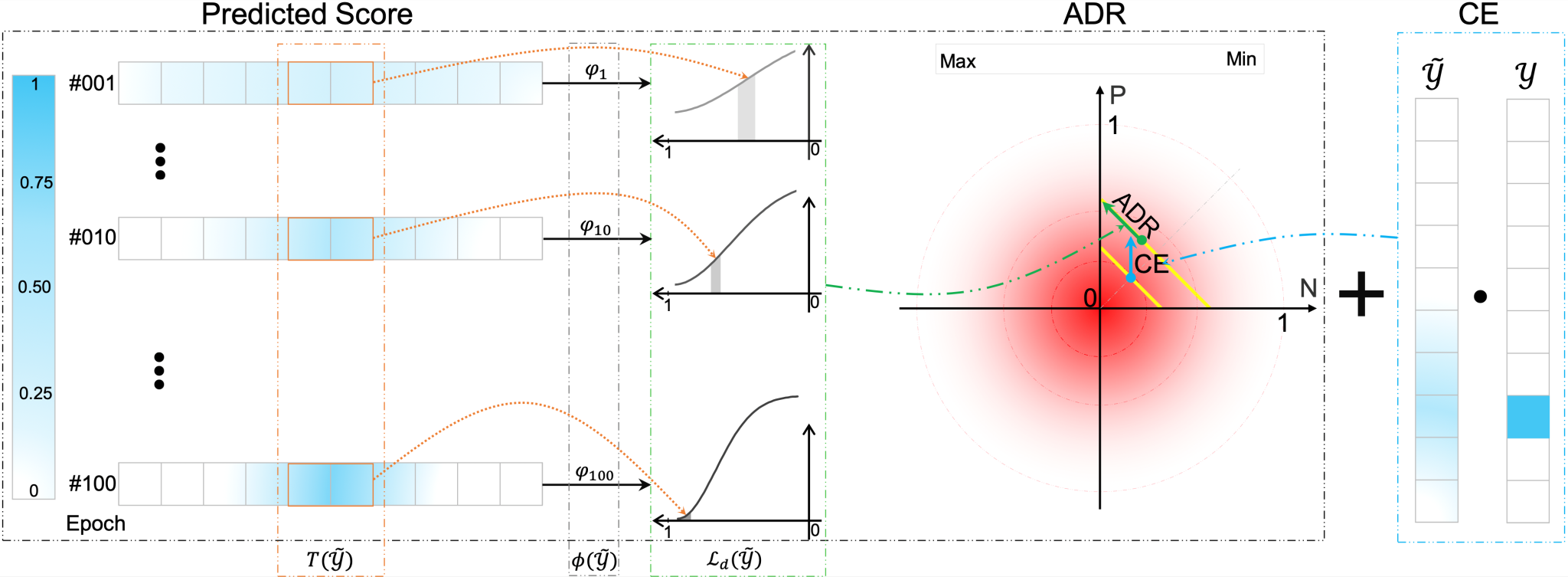
然而,这些方法并没有充分利用不同类别之间的相似性,因为它们刻板地遵循类别独立且同分布的假设。在本文中,我们接受了现实世界数据分布的设定,即由于外观或概念的相似性,一些类别之间存在语义重叠。基于这一假设,我们提出了一种新颖的正则化方法来改进辨别学习,如下图所示,我们首先根据样本的语义邻近类别来校准其估计的最高可能性,然后通过施加自适应指数惩罚来鼓励整体可能性预测具有确定性。由于所提出方法的梯度大致与预测可能性的不确定性成比例,我们将其命名为自适应辨别正则化(ADR),并与分类中的标准交叉熵损失一起进行训练。
大量实验证明ADR在各种视觉分类任务(超过10个基准)中能够产生一致且明显的性能提升。此外,我们发现ADR对长尾和噪声标签数据分布具有鲁棒性。其灵活的设计使其与主流分类架构和损失函数兼容。