祝贺实验室团队硕士生季晨皓一篇论文“DiffPano: Scalable and Consistent Text to Panorama Generation with Spherical Epipolar-Aware Diffusion”被The Thirty-eighth Annual Conference on Neural Information Processing Systems录用。
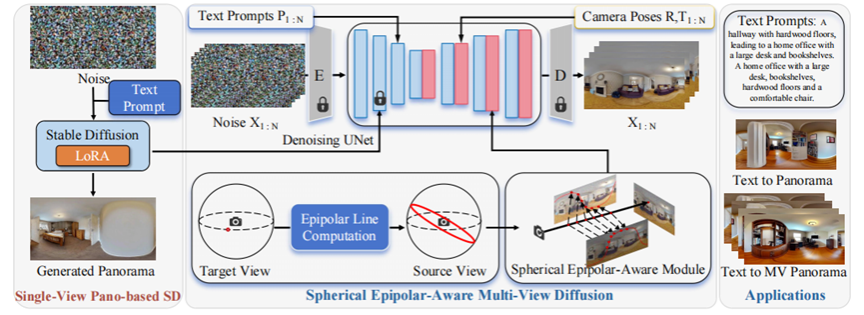
基于扩散的方法在2D图像或3D对象生成方面取得了显著的成就,然而,3D场景甚至360度图像的生成仍然受到限制,这是由于场景数据集的数量有限、3D场景本身的复杂性,以及生成一致的多视角图像的难度。为了解决这些问题,我们首先建立了一个大规模的全景视频-文本数据集,该数据集包含数百万连续的全景关键帧,这些关键帧附带有对应的全景深度、相机姿态和文本描述。接着,我们提出了一个新的文本驱动的全景生成框架,称为DiffPano,以实现可扩展、一致且多样化的全景场景生成。具体来说,利用稳定扩散的强大生成能力,我们在所建立的全景视频-文本数据集上使用LoRA对单视角文本到全景的扩散模型进行了微调。我们进一步设计了一个球面极线感知的多视角扩散模型,以确保生成的全景图像的多视角一致性。广泛的实验表明,DiffPano能够根据给定的未见文本描述和相机姿态生成可扩展、一致且多样化的全景图像。