祝贺实验室博士生陈雪宇一篇论文“Improving Long-Context Summarization with Multi-Granularity Retrieval Optimization”被AAAI2026录用。
检索增强生成(RAG)能有效扩展大型语言模型的知识边界并增强其获取实时信息的能力,是应对LLM局限性的一项关键技术。然而,现有的RAG方法通常是基于孤立的文本片段,缺乏文档内信息整合的能力。受人类认知过程的启发:在阅读文本时自然会整合并总结之前的知识,逐步形成全面的理解。在该工作中,我们提出了层次化两阶段基于摘要的RAG方法(HTSIR),在检索之前对语料库进行预处理,通过对连续文本进行摘要,构建包含不同粒度信息的检索树。随后,基于当前问题,利用重排序器对检索到的信息进行进一步处理,将其作为大型语言模型的上下文输入。此外,由于单步摘要在基于摘要的查询任务中常常不够精确,我们进一步引入了Refinement模块,允许大型语言模型自主反思并修正输出。在四个问答数据集上的实验,充分验证了我们的方法在长文本任务上的优越性及其对开源与闭源大模型的强大通用性。

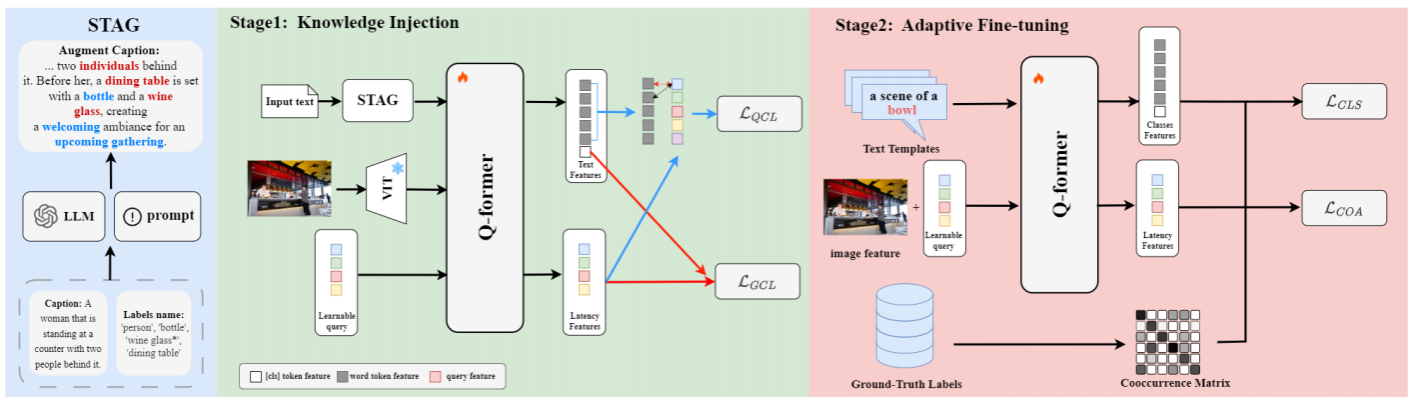
祝贺实验室硕士生李勇成一篇论文“Dual-Phase Visual-Language Pretraining and Adaptation for Long-Tailed Multi-Label Recognition”被AAAI2026录用。
在该工作中,我们提出了 DP-VLPA,这是一种用于解决长尾多标签识别问题的新颖的双阶段视觉语言预训练和适配框架。长尾多标签识别(LTML)是一项关键但具有挑战性的任务,其核心问题在于:罕见“尾部”类别的训练样本严重匮乏,以及标签之间复杂的共现模式常常导致模型出现偏差。具体而言,我们设计并实现了一个双阶段视觉语言预训练与自适应框架 (DP-VLPA)。该框架的核心思想是:先利用大型语言模型(LLM)的外部世界知识为模型建立一个无偏、知识丰富的基础,再通过精心设计的微调策略,将这些知识有效应用于解决长尾分类任务。在第一阶段,我们的结构化尾部感知生成(STAG)模块利用大型语言模型(LLM)生成详细描述,明确强调尾部类别及其上下文关系,从而提供强大且偏差较小的特征基础。在第二阶段的适配过程中,我们确保这些知识能够得到有效应用。动态查询重加权(DQR)机制迫使模型关注关键的尾部类别证据。同时,共现感知(COA)损失明确教导模型标签之间的统计依赖关系,纠正共现偏差。在两大权威长尾识别基准 VOC-LT 和 COCO-LT 上,我的DP-VLPA框架的mAP分别达到了 90.72% 和 74.42%。该性能全面超越了以往的所有方法(包括纯视觉模型和视觉语言模型),取得了该领域的 State-of-the-Art (SOTA) 成果,验证了“主动知识注入”范式的有效性。
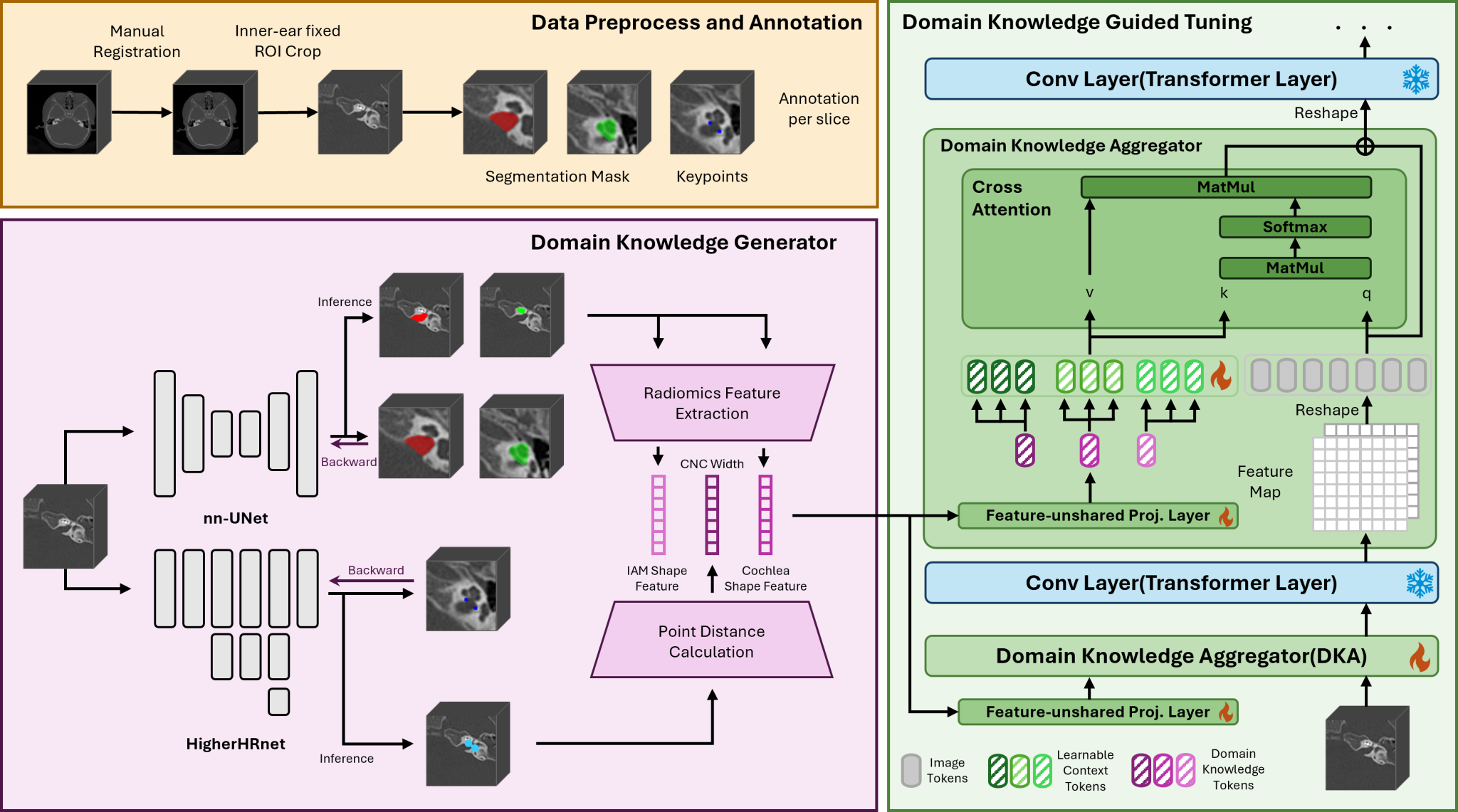
祝贺实验室硕士生万唯循一篇论文“Tuning Medical Foundation Models for Inner Ear Temporal CT Analysis with Plug-and-play Domain Knowledge Aggregator”被AAAI2026录用。
本工作针对内耳CT影像分析中标注数据稀缺与临床知识难以融入的问题,提出了一种Domain Knowledge Guided Tuning (DKGT) 框架。该方法通过设计一个可插拔的领域知识聚合器(Domain Knowledge Aggregator, DKA),实现对医学基础模型的统一适配与领域知识注入。具体而言,DKGT首先从临床关键结构(如内听道、耳蜗及蜗神经管)中提取放射组学特征,将其编码为领域知识token;随后,DKA利用跨注意力机制在多层网络中实现知识token与影像特征的交互,从而在冻结基础模型权重的前提下实现高效调优与多层次知识融合。该框架具有架构无关性,可与多种医学基础模型(如SAM-Med3D、CT-FM、Merlin)无缝结合。实验结果表明,DKGT在听力恢复预测及结构异常检测等任务上显著优于现有的全量微调与参数高效微调方法,展现出更强的泛化能力与临床可解释性。
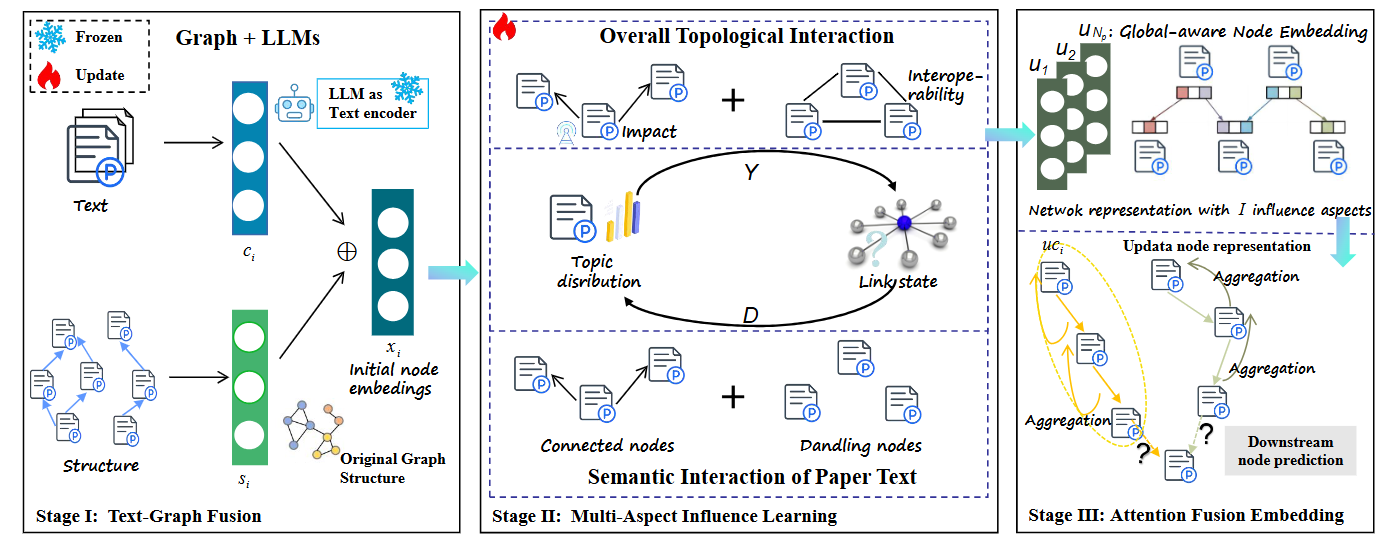
祝贺实验室博士生陈雪宇一篇论文“Beyond Topology-based Graph Mining: Deep Analysis Research Networks via Evolutionary Topology and Content Fusion”被Information Fusion录用。
学术数据(如学术论文与专利)挖掘任务旨在从日益增长的研究文献中提取有价值的信息,以揭示知识关联。然而,现有研究在分析引用动机方面存在局限,且主要关注文献间的成对关系,这制约了知识传播的准确预测与可解释分析。为解决这些问题,我们提出基于引文网络的图文本模型(GTCN),该模型利用大语言模型学习文本信息并探究引用背后的深层动机。具体来说,通过引入渐进式学习策略来捕捉全局网络结构,生成能反映多方面影响的节点嵌入。在此基础上,进一步提出注意力融合嵌入模块,该模块沿语义化引文路径聚合节点表征,从而建模特定方面的影响力。这一方法有效克服了传统方法仅关注二元关系预测的局限,能够深入探索不同研究背景下的技术发展路径。我们在五个数据集(包含学术论文和专利引文网络)上开展实验,将典型的成对链接预测任务扩展为路径感知的N路径预测任务。在节点分类任务中,GTCN也取得了最先进的结果。所展现的可解释分析能力,验证了其在引文网络分析与研究数据挖掘中的巨大应用潜力。