祝贺实验室团队博士生赵青松一篇论文 “Does Video-Text Pretraining Help Open-Vocabulary Online Action Detection?” 被The Thirty-eighth Annual Conference on Neural Information Processing Systems录用。
传统的在线动作检测方法主要针对离线场景,依赖封闭集合的分类和定位,且需要手动标注所有动作类别。这限制了其在实际应用中的适用性,尤其是在需要实时理解的场景,例如监控。OV-OAD通过引入对象中心解码器单元,使用视频-文本对应关系自动聚合具有相似语义的帧,从而克服了这些限制。
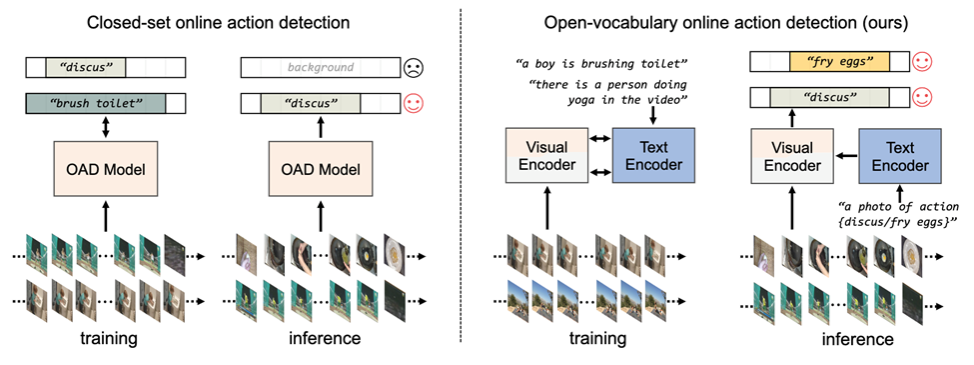
我们提出了一种名为OV-OAD的新型零样本在线动作检测模型,该模型利用视觉-语言模型和文本监督,无需手动标注即可学习。OV-OAD在THUMOS’14和TVSeries两个动作检测基准数据集上取得了较好的识别性能,为开放世界场景下的实时动作理解提供了可扩展的解决方案。我们的OV-OAD模型的优势在于:1)开放词汇, 无需手动标注即可识别任意动作类别。2)零样本学习, 无需在下游数据集上进行微调即可进行动作检测。3)实时性,适用于需要实时动作理解的场景,例如全场景监控。OV-OAD模型的提出为开放世界场景下的实时动作理解开辟了新的途径,并为相关领域的研究和应用提供了重要的参考价值。

