祝贺实验室团队博士生宋子帆一篇论文 “AlchemistCoder: Harmonizing and Eliciting Code Capability by Hindsight Tuning on Multi-source Data被The Thirty-eighth Annual Conference on Neural Information Processing Systems录用。
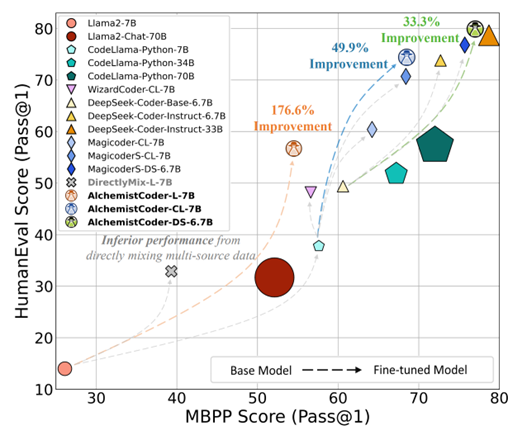
开源大型语言模型(LLMs)及其垂域变体,特别是代码LLMs,最近展现了令人印象深刻的性能。然而,先前的代码LLMs通常在单一来源数据上进行微调,且质量和多样性有限,这可能不足以充分挖掘预训练代码LLMs的潜力。本文提出了炼金术士大模型(AlchemistCoder),一系列在多源数据上微调的代码LLMs,具备增强的代码生成和泛化能力。为此,我们首次揭示了多源代码语料库中各种风格和质量之间的内在冲突,并引入了数据特定的提示,采用回溯重标定,称为炼金提示(AlchemistPrompts),以协调不同数据源和指令-响应对。此外,我们建议将数据构建过程纳入微调数据,作为代码理解任务,包括指令进化、数据过滤和代码审查。大量实验表明,AlchemistCoder在同等规模(6.7B/7B)的所有模型中明显领先,并与更大模型(15B/33B/70B)性能相当甚至超越,展示了我们方法在提升指令跟随能力和推动开源代码智能边界方面的有效性。