新年的钟声即将敲响,告别充满收获的2024年,我们迎来了充满希望的2025年。感谢各位领导、老师和同行对我们实验室的关心和支持,春节好!在这辞旧迎新之际,衷心祝愿实验室全体师生新年快乐、身体健康、科研顺利、生活美满!同时,也向已经毕业的同学们致以最美好的祝福!愿你们在新的岗位上大展宏图,书写属于自己的精彩篇章。无论身处何地,实验室永远是你们的坚强后盾和温暖港湾。新的一年,让我们继续携手努力,不忘初心,追求卓越,共同创造更辉煌的成绩!2025,加油!🎉
过去一年,实验室佳讯频传,共发表NeurIPS,ECCV,ICLR等高水平会议论文8篇(NeurIPS*4,ECCV*2,ICLR*2),TPAMI,IJCV,TIP,TMM,PR等高水平期刊论文共7篇(TPAMI*1,IJCV*3,TIP*1,TMM*1,PR*1)。其中包括最近刚刚录用的三篇重要成果:
祝贺实验室团队硕士研究生杨志远一篇论文 “Fusion4DAL: Offline Multi-modal 3D Object Detection for 4D Auto-labeling"被International Journal of Computer Vision (IJCV)录用。
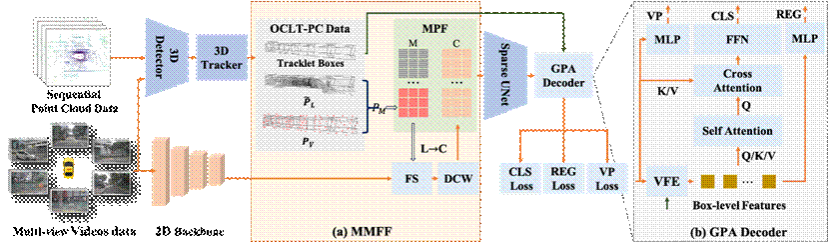
离线长时序3D目标检测器是实现自动驾驶3D目标检测数据自动标注的重要组件之一。与现有的在线3D目标检测方法相比,离线检测器能够充分利用整个序列数据(如视频或连续点云),并通过时序上下文信息显著提升检测性能。尽管融合LiDAR和相机信息已成为自动驾驶3D目标检测的常用方法,但多模态融合在离线4D检测领域的潜力尚未得到充分挖掘。通过实验分析,我们发现其主要问题源于以下两个方面:(1)点云的稀疏性限制了长时序图像特征的提取,导致信息丢失;(2)部分LiDAR点在图像中可能被遮挡,从而引入不准确的图像特征。
针对上述问题,本文提出了一种简单而高效的离线多模态3D目标检测方法,命名为Fusion4DAL,专为长时序多模态4D自动标注设计。具体而言,为解决目标内部点云稀疏性问题,我们提出了多模态混合特征融合模块(MMFF)。该模块通过在密集3D网格中引入虚拟点,并将其与真实LiDAR点结合,生成混合点以提取密集的点级图像特征。这种方法有效增强了多模态特征融合能力,避免了稀疏LiDAR点的限制。此外,针对LiDAR点被遮挡的问题,我们利用目标间的遮挡关系,确保LiDAR点与其对应深度特征图之间的深度一致性,从而过滤掉错误的图像特征。为了进一步区分混合点类型并保持目标的几何形状,我们定义了虚拟点损失(VP Loss)。同时,为实现长时序感受野并捕捉更细粒度的特征,我们设计了全局点注意力(GPA)解码器,其中包含框级自注意力模块和全局点注意力模块。
实验结果表明,Fusion4DAL在nuScenes和Waymo数据集上均超越了当前最先进的离线3D检测方法,并在降低人工标注成本方面展现出显著的优势。
祝贺实验室团队硕士研究生王雨滨一篇论文 “Uni2Det: Unified and Universal Framework for Prompt-Guided Multi-dataset 3D Detection” 被The ThirteenthInternational Conference on Learning Representations(ICLR)录用。
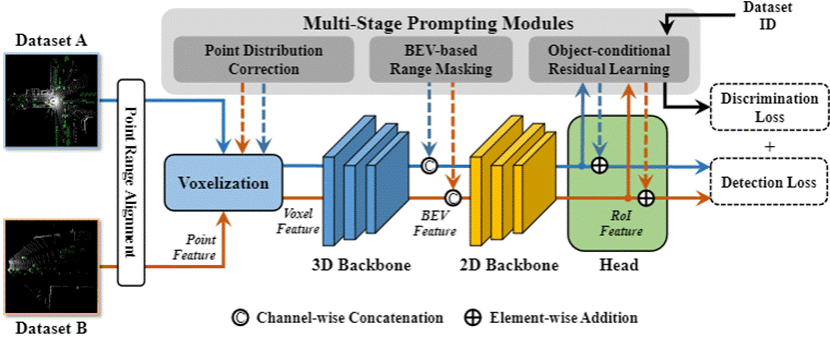
本文提出了Uni2Det,一个全新的框架,用于实现统一和通用的多数据集训练,特别应用于3D检测任务,从而提高不同领域中的鲁棒性表现,并增强对未见领域的泛化能力。由于不同领域中的数据分布和分类体系存在显著差异,仅仅通过数据集融合来训练检测器会面临巨大的挑战。针对这一问题,本文引入了一个多阶段提示模块,该模块通过根据不同数据集的特点提供相应的提示,来减少各数据集间的差异。这一创新设计使得在多个先进的3D检测框架中,能够以统一的方式进行无缝集成,同时也简化了不同数据集之间适配的过程。通过在KITTI、Waymo和nuScenes等多个数据集整合场景中的实验验证,Uni2Det在多数据集训练中明显优于现有方法。其中,零样本跨数据集迁移的实验结果进一步验证了本方法的优越泛化能力。
祝贺实验室团队博士生高俊尧一篇论文 “FaceShot: Bring Any Character into Life” 被The ThirteenthInternational Conference on Learning Representations(ICLR)录用。
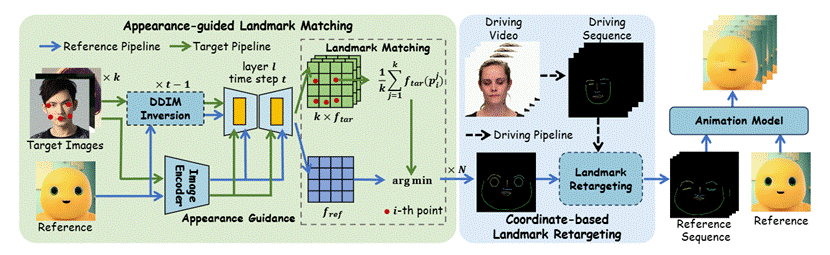
本文提出了FaceShot,一种全新的免训练的肖像动画框架,能够通过任意驱动视频,将任意角色(包括真实人物和风格化角色)赋予生命,而无需进行微调或重新训练。FaceShot的核心由两个模块组成:基于外观引导的关键点匹配模块和基于坐标的关键点重定向模块。这两个模块结合了潜变量扩散模型的鲁棒语义对应能力,生成了高精度且稳定的重定向关键点序列,可适应多种角色类型的面部运动序列。
生成的关键点序列随后输入到预训练的关键点驱动动画模型中,用于生成动画视频。得益于这一强大的泛化能力,FaceShot突破了传统肖像关键点检测的局限,能够适配任意风格化角色和驱动视频,从而显著扩展了肖像动画的应用范围。此外,FaceShot具有高度兼容性,可以无缝集成到任何关键点驱动的动画模型中,从而大幅提升整体性能。
为了验证方法的有效性,本文构建了一个全新的角色基准数据集CharacBench,并通过大量实验表明,FaceShot在各种角色领域中始终优于当前最先进的方法。
URL:https://faceshot2024.github.io/faceshot/

